Two LLMs, Mistral 7B and Mixtral 8x7B from Mistral AI, outperform other models like Llama and GPT-3 across benchmarks while providing faster inference and longer context handling capabilities.
Image is subject to copyright!
A French startup, Mistral AI has released two impressive large language models (LLMs) – Mistral 7B and Mixtral 8x7B. These models push the boundaries of performance and introduce a better architectural innovation aimed at optimizing inference speed and computational efficiency.
Mistral 7B: Small yet Mighty
Mistral 7B is a 7.3 billion parameter transformer model that punches above its weight class. Despite its relatively modest size, it outperforms the 13 billion parameters Llama 2 model across all benchmarks. It even surpasses the larger 34 billion parameter Llama 1 model on reasoning, mathematics, and code generation tasks.
Two foundations of Mistral 7B’s efficiency:
Grouped Query Attention (GQA) Sliding Window Attention (SWA)
GQA significantly accelerates inference speed and reduces memory requirements during decoding by sharing keys and values across multiple queries within each transformer layer.
SWA, on the other hand, enables the model to handle longer input sequences at a lower computational cost by introducing a configurable “attention window” that limits the number of tokens the model attends to at any given time.
Name
Number of parameters
Number of active parameters
Min. GPU RAM for inference (GB)
Mistral-7B-v0.2
7.3B
7.3B
16
Mistral-8X7B-v0.1
46.7B
12.9B
100
How Do (LLM) Large Language Models Work? Explained
A large language model (LLM) is an AI system trained on extensive text data, designed to produce human-like and intelligent responses.

Mixtral 8x7B: A Sparse Mixture-of-Experts Marvel
While Mistral 7B impresses with its efficiency and performance, Mistral AI took things to the next level with the release of Mixtral 8x7B, a 46.7 billion parameter sparse mixture-of-experts (MoE) model. Despite its massive size, Mixtral 8x7B leverages sparse activation, resulting in only 12.9 billion active parameters per token during inference.
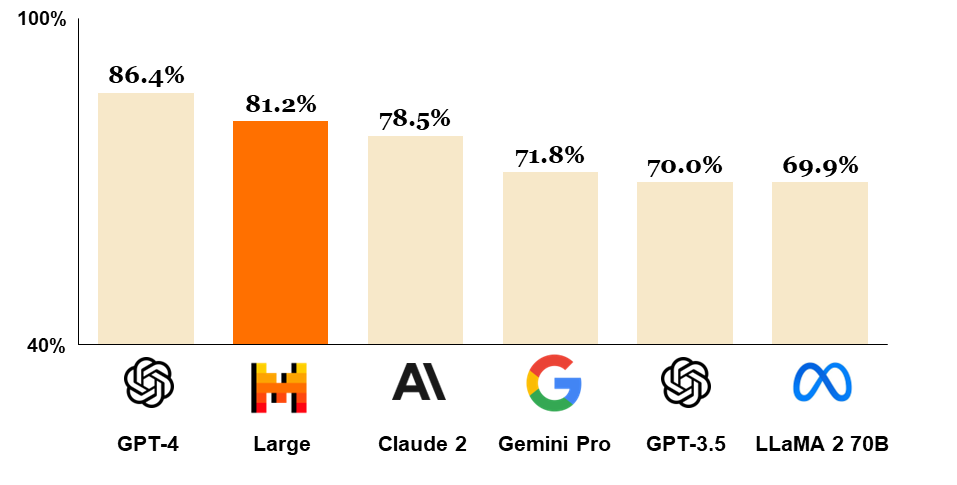 Image Credit: Mistral.ai
Image Credit: Mistral.ai
The key innovation behind Mixtral 8x7B is its MoE architecture. Within each transformer layer, the model has eight expert feed-forward networks (FFNs). For every token, a router mechanism selectively activates just two of these expert FFNs to process that token. This sparsity technique allows the model to harness a vast parameter count while controlling computational costs and latency.
According to Mistral AI’s benchmarks, Mixtral 8x7B outperforms or matches the large language models like Llama 2 70B and GPT-3.5 across most multiple tasks, including reasoning, mathematics, code generation, and multilingual benchmarks. Additionally, it provides 6x faster inference than Llama 2 70B, thanks to its sparse architecture.
Should You Use Open Source Large Language Models?
The benefits, risks, and considerations associated with using open-source LLMs, as well as the comparison with proprietary models.
Both Mistral 7B and Mixtral 8x7B are good at code generation tasks like HumanEval and MBPP, with Mixtral 8x7B having a slight edge and it’s better. Mixtral 8x7B also supports multiple languages, including English, French, German, Italian, and Spanish, making them valuable assets for multilingual applications.
On the MMLU benchmark, which evaluates a model’s reasoning and comprehension abilities, Mistral 7B performs equivalently to a hypothetical Llama 2 model over three times its size.
What is Vector Database and How does it work?
Vector databases are highly intriguing and offer numerous compelling applications, especially when it comes to providing extensive memory.
LLMs Benchmark Comparison Table
Model
Average MCQs
Reasoning
Python coding
Future Capabilities
Grade school math
Math Problems
Claude 3 Opus
84.83%
86.80%
95.40%
84.90%
86.80%
95.00%
Gemini 1.5 Pro
80.08%
81.90%
92.50%
71.90%
84%
91.70%
Gemini Ultra
79.52%
83.70%
87.80%
74.40%
83.60%
94.40%
GPT-4
79.45%
86.40%
95.30%
67%
83.10%
92%
Claude 3 Sonnet
76.55%
79.00%
89.00%
73.00%
82.90%
92.30%
Claude 3 Haiku
73.08%
75.20%
85.90%
75.90%
73.70%
88.90%
Gemini Pro
68.28%
71.80%
84.70%
67.70%
75%
77.90%
Palm 2-L
65.82%
78.40%
86.80%
37.60%
77.70%
80%
GPT-3.5
65.46%
70%
85.50%
48.10%
66.60%
57.10%
Mixtral 8x7B
59.79%
70.60%
84.40%
40.20%
60.76%
74.40%
Llama 2 – 70B
51.55%
69.90%
87%
30.50%
51.20%
56.80%
Gemma 7B
50.60%
64.30%
81.2%
32.3%
55.10%
46.40%
Falcon 180B
42.62%
70.60%
87.50%
35.40%
37.10%
19.60%
Llama 13B
37.63%
54.80%
80.7%
18.3%
39.40%
28.70%
Llama 7B
30.84%
45.30%
77.22%
12.8%
32.6%
14.6%
Grok 1
–
73.00%
–
63%
–
62.90%
Qwen 14B
–
66.30%
–
32%
53.40%
61.30%
Mistral Large
–
81.2%
89.2%
45.1%
–
81%
This model comparison table was last updated in March 2024. Source
When it comes to fine-tuning for specific use cases, Mistral AI provides “Instruct” versions of both models, which have been optimized through supervised fine-tuning and direct preference optimization (DPO) for careful instruction following.
👍
The Mixtral 8x7B Instruct model achieves an impressive score of 8.3 on the MT-Bench benchmark, making it one of the best open-source models for instruction.
Deployment and Accessibility
Mistral AI has made both Mistral 7B and Mixtral 8x7B available under the permissive Apache 2.0 license, allowing developers and researchers to use these models without restrictions. The weights for these models can be downloaded from Mistral AI’s CDN, and the company provides detailed instructions for running the models locally, on cloud platforms like AWS, GCP, and Azure, or through services like HuggingFace.
LLMs Cost and Context Window Comparison Table
Models
Context Window
Input Cost / 1M tokens
Output Cost / 1M tokens
Gemini 1.5 Pro
128K
N/A
N/A
Mistral Medium
32K
$2.7
$8.1
Claude 3 Opus
200K
$15.00
$75.00
GPT-4
8K
$30.00
$60.00
Mistral Small
16K
$2.00
$6.00
GPT-4 Turbo
128K
$10.00
$30.00
Claude 2.1
200K
$8.00
$24.00
Claude 2
100K
$8.00
$24.00
Mistral Large
32K
$8.00
$24.00
Claude Instant
100K
$0.80
$2.40
GPT-3.5 Turbo Instruct
4K
$1.50
$2.00
Claude 3 Sonnet
200K
$3.00
$15.00
GPT-4-32k
32K
$60.00
$120.00
GPT-3.5 Turbo
16K
$0.50
$1.50
Claude 3 Haiku
200K
$0.25
$1.25
Gemini Pro
32K
$0.125
$0.375
Grok 1
64K
N/A
N/A
This cost and context window comparison table was last updated in March 2024. Source
💡
Largest context window: Claude 3 (200K), GPT-4 Turbo (128K), Gemini Pro 1.5 (128K)
💲
Lowest input cost per 1M tokens: Gemini Pro ($0.125), Mistral Tiny ($0.15), GPT 3.5 Turbo ($0.5)
For those looking for a fully managed solution, Mistral AI offers access to these models through their platform, including a beta endpoint powered by Mixtral 8x7B.
DevOps vs SRE vs Platform Engineering – Explained
At small companies, engineers often wear multiple hats, juggling a mix of responsibilities. Large companies have specialized teams with clearly defined roles in DevOps, SRE, and Platform Engineering.

Conclusion
Mistral AI’s language models, Mistral 7B and Mixtral 8x7B, are truly innovative in terms of architectures, exceptional performance, and computational efficiency, these models are built to drive a wide range of applications, from code generation and multilingual tasks to reasoning and instruction.
How does the Groq’s LPU work?
Each year, language models double in size and capabilities. To keep up, we need new specialized hardware architectures built from the ground up for AI workloads.
